






京都大学×漢検 研究プロジェクト
人工知能(AI)による漢字・日本語学習研究
研究目的
「漢検」は、年間約200万人、累計約4,000万人の受検者を抱えており、設問1問に対し数万を超える解答データを保有しているが、これまで受検者の解答データを充分に分析するには至らなかった。このような解答データをはじめ、当協会には、検定やその他の学習支援活動を通じて蓄積されたノウハウや材料が多く存在していたが、それらを分析し学習材料を提供することで、学習者や学習指導者をはじめ広く社会一般に対して有益な情報として還元したいとの思いがあった。
本研究では、自然言語処理研究の伝統と言語処理ツールの公開等の実績をもつ京都大学が、当協会の保有する出題ノウハウや採点結果等を、人工知能(AI)やその他の技術によって解析する。当協会の提供する膨大なデータをもとに、京都大学の大規模コーパス・解析システムを合わせて活用することで、語彙の難易度や関連度の指標化、誤答の分類、学習者レベルに応じた妥当性の高い学習指針の提供を目指す。これにより、検定受検者のみならず漢字・日本語学習者の学習意欲を喚起し、語彙や漢字能力獲得の機会を最大化することを目的とする。
研究体制
| 京都大学大学院情報学研究科 | 教授 | 黒橋 禎夫 |
| 准教授 | 河原 大輔 | |
| 講師 | 延原 章平 | |
| ほか研究協力者 | ||
| (公財)日本漢字能力検定協会 | 研究プロジェクトチーム | |
概要とプロセス
2017年度 研究実施方法の確定、仮説設定および検証の開始
2018年度 語彙難易度表(第一案)の策定、語彙関連度分類の実施、誤答分析の実施
2019年度 語彙関連分類(第一案)の策定、誤答分析等に関する公表
研究途中経過
■『自然言語処理』Vol.30 No.4(2023年12月15日[金])にて論文を発表/2023年度 言語処理学会 論文賞を受賞
大村 和正, 河原 大輔, 黒橋 禎夫. 基本イベントに基づく常識推論データセットの構築と利用. 自然言語処理 Vol.30 No.4.2023
論文は(PDF)こちら![]()
■ICCE2023(2023年12月4日[月]~12月8日[金]/島根県 松江市 くにびきメッセ)にて論文を発表
Kazumasa Omura, Kei Kubo, Frederic Bergeron, and Sadao Kurohashi: Toward Game-Based Learning of Japanese Writing for Elementary School Students, Proceedings of the 31st International Conference on Computers in Education (ICCE2023).
論文は(PDF)こちら![]()
■COLING 2022(2022年10月12日[水]~10月17日[月]/韓国 慶州市)にて論文を発表/Outstanding Paper に選定
Kazumasa Omura and Sadao Kurohashi: Improving Commonsense Contingent Reasoning by Pseudo-data and its Application to the Related Tasks, Proceedings of the 29th International Conference on Computational Linguistics (COLING 2022).
論文(PDF)はこちら![]()
■言語処理学会第28回年次大会(2022年3月14日[月]~3月18日[金]/オンライン)にて論文を発表
大村 和正, 黒橋 禎夫. 疑似問題による常識推論能力の改善と関連タスクへの効果. 言語処理学会 第28回年次大会, 2022.
論文(PDF)はこちら![]()
■言語処理学会第27回年次大会(2021年3月15日[月]~3月19日[金]/オンライン)にて論文を発表
大村 和正, 久保 圭, 黒橋 禎夫. ことばつなぎゲーム:ゲーミフィケーションによる小学生の作文教育. 言語処理学会 第27回年次大会, 2021.
論文(PDF)はこちら![]()
■EMNLP 2020(2020年11月16日[火]~11月20日[金]/オンライン)にて論文を発表
Kazumasa Omura, Daisuke Kawahara and Sadao Kurohashi: A Method for Building a Commonsense Inference Dataset based on Basic Events, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), (2020.11).
論文(PDF)はこちら![]()
■言語処理学会第26回年次大会(2020年3月16日[月]~3月19日[木]/オンライン)にて論文を発表
大村 和正, 河原 大輔, 黒橋 禎夫. 基本イベントに基づく常識推論データセットの構築. 言語処理学会 第26回年次大会, 2020.(修正版)
論文(PDF)はこちら![]()
■言語処理学会第25回年次大会(2019年3月12日[火]~3月15日[金]/名古屋大学 東山キャンパス)にて論文を発表
岡久太郎, 久保圭, 水谷勇介, 河原大輔, 黒橋禎夫. クラウドソーシングにより収集した語釈文を基にした単語の基本度推定. 言語処理学会第25回年次大会, pp.1499-1502, 2019.
論文(PDF)はこちら![]()
■言語処理学会第25回年次大会(2019年3月12日[火]~3月15日[金]/名古屋大学 東山キャンパス)にて論文を発表
水谷勇介, 河原大輔, 黒橋禎夫. クラウドソーシングを用いた習得時期の想起質問に基づく単語難易度データベースの構築. 言語処理学会 第25回年次大会,pp.1503-1506, 2019.
論文(PDF)はこちら![]()
■言語処理学会第24回年次大会(2018年3月12日[月]~3月16日[金]/岡山コンベンションセンター)にて論文を発表
水谷勇介, 河原大輔, 黒橋禎夫. 日本語単語の難易度推定の試み. 言語処理学会 第24回年次大会, pp.670-673, 2018.
論文(PDF)はこちら![]()
研究成果
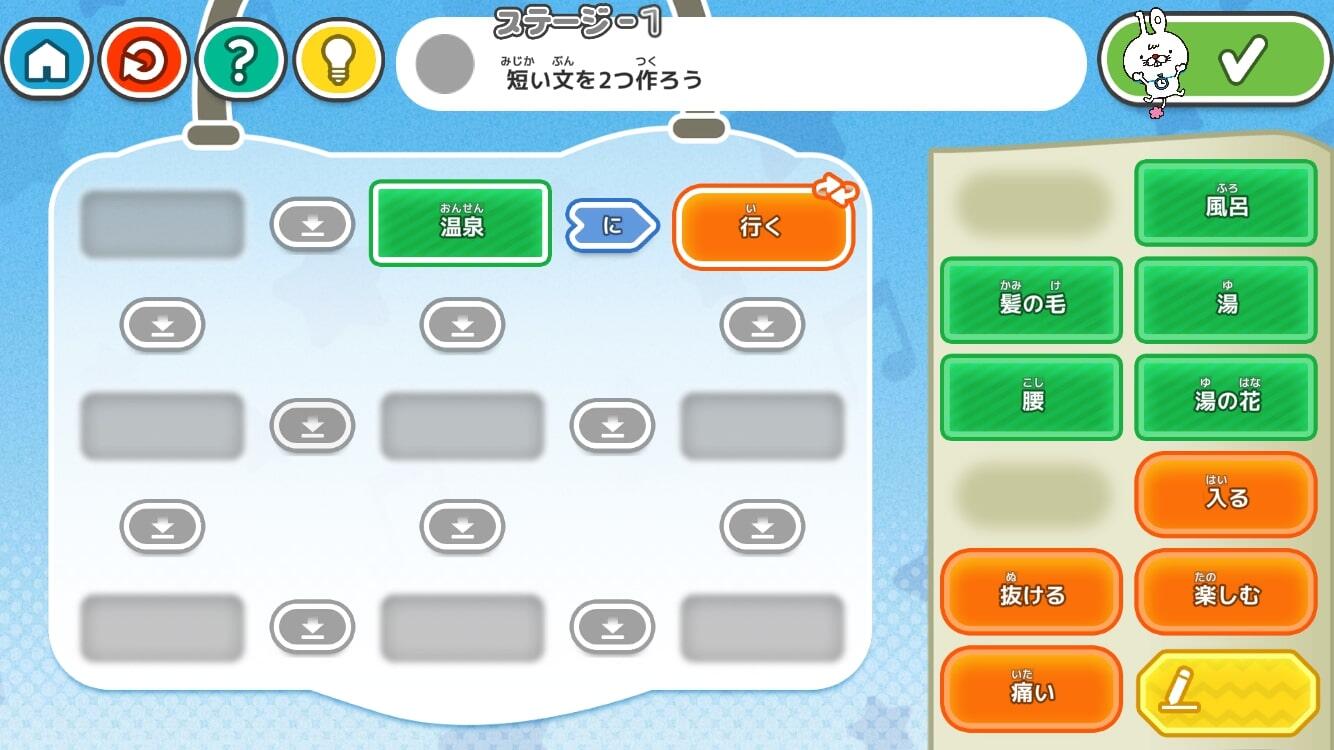
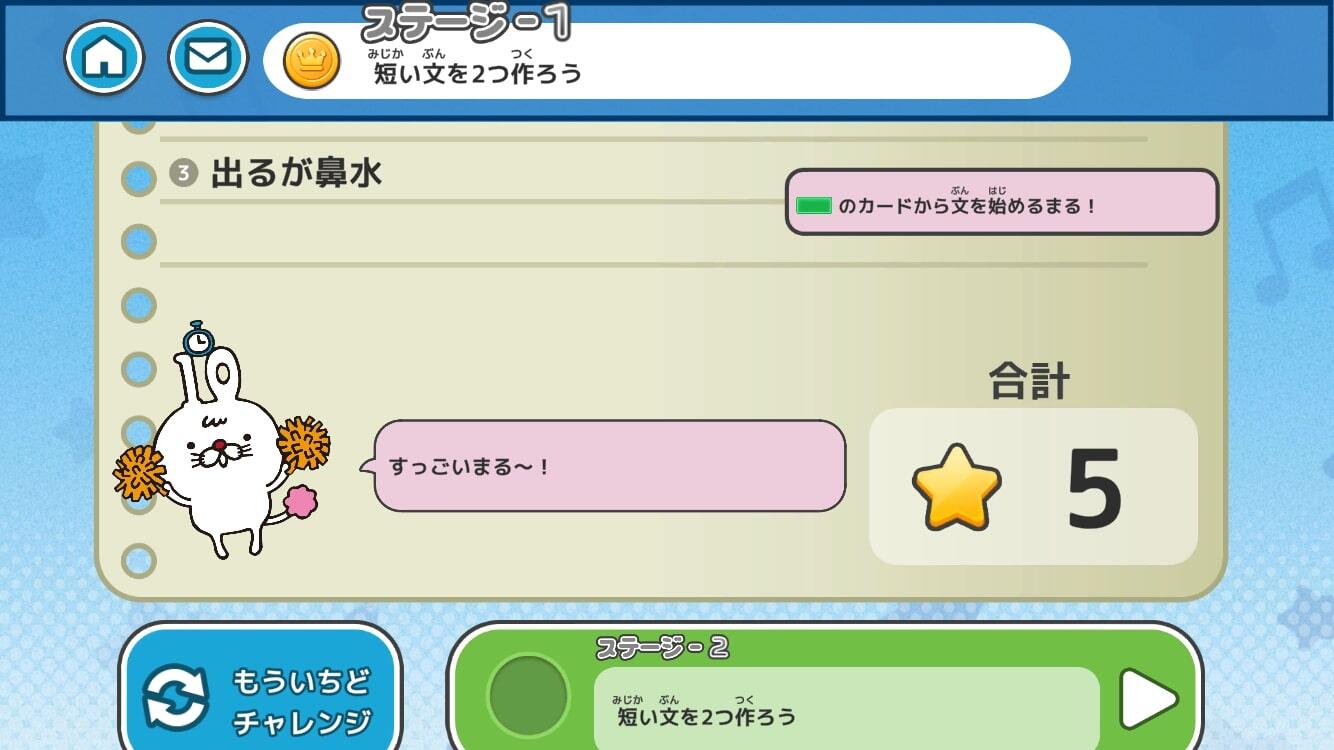
■作文学習アプリ『いちまるとはじめよう!ことばむすび』を配信(2022年1月25日)
本アプリは2024年3月21日よりサービスを一時停止しております。再開については改めてHP等で告知いたします。
|
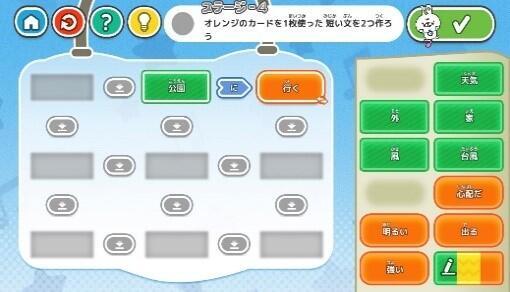
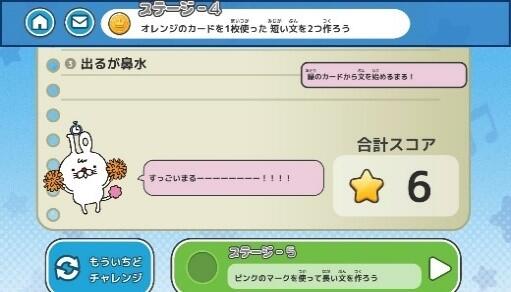
・パズルのようにかんたんに文を作る体験ができる
|

アプリイメージ



■漢字学習アプリ『漢検とニュース』を配信(2019年4月1日)
本アプリは2024年3月21日よりサービスを一時停止しております。再開については改めてHP等で告知いたします。
 |
・最新ニュースで漢字学習ができる無料アプリ (協力:読売新聞社)
|
アプリイメージ








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}